Machine Learning & AI / Case Study
Daemon brings AI startup Conjecture's AI inference ecosystem into AWS
.jpg)
Conjecture is an ambitious startup looking to make AI safer, developing advanced core tools, models and products. We helped them integrate and host their powerful custom models and serving code, so that they can benefit from AWS' high-performance ML inference ecosystem.
The Client
Conjecture is a fast-growing agile startup that aims to change the landscape of AI. They were born out of a group of hackers in the open-source community and have set a bold research and product development agenda for themselves. They are conducting innovative research in cognitive emulation. As a startup, Conjecture built out a variety of AI-powered products, training large foundation AI models, and creating cutting-edge generative AI hosting and application solutions. These products included the Axiom end-to-end low latency voice chat solution and API and the Cubed/Hypercubed AI-powered workflow and coding assistant. These products and their capabilities are being folded into Conjecture's flagship cognitive emulation platform.
AWS is keen to support Conjecture in its mission and expects Conjecture to grow its business around the AWS suite of products and compute offerings.
The Challenge
When working with AI inference at scale, performance, from GPU bandwidth to network latency, cost performance, and scalability are key concerns. Conjecture wants to deploy its custom AI models on AWS to improve the performance, cost performance, and scalability of its products and services. It is looking for ways to leverage the services it uses to iterate rapidly in both product development and research. With a plethora of AI models they want to make available to services and customers at any given moment, and many more fine-tuned versions, they are looking for ways to keep the costs of any deployment down.
Our Approach
Daemon worked closely with both Conjecture and AWS account teams to get the best value for Conjecture with AWS AI and cloud services.
We initiated the project with a comprehensive discovery and proof of concept phase. This involved bringing Conjecture's speech-to-text engine into two different AWS services (ECS/EC2 and Sagemaker). Additionally, we developed a proof of concept deployment of Conjecture's application layer in ECS/Fargate and RDS and integrated it with one of the models we deployed. Our aim was to ensure we could support Conjecture's use case in the user-friendly Sagemaker and provide assurance around a fallback to the more configurable ECS/EC2, given Conjecture's cutting-edge work.
We discussed the pros and cons of the different approaches with Conjecture's experts, considering Conjecture's present business direction and Sagemaker's current and future capabilities. Conjecture opted to migrate its models to Sagemaker in the first instance because of its ease of use and promise of quick iteration.
We developed a plan to migrate the remainder of Conjecture's models (including various large language models as well as their text-to-speech model) to set up the infrastructure, security, and deployment tools that they will need to reliably scale this for many customers.
Conjecture was looking to use the hosted AI models to provide services to a variety of different clients, so to enable their services to dynamically load, use and unload models into Sagemaker according to demand, we built a Sagemaker integration component in Conjecture's application layer. This allowed Conjecture to deploy their models online and automatically scale them to zero when not in use. When hosting their own models, startups often request this feature so that they can build out workloads while keeping costs down in the early stages of growing demand for their services. Also in the interest of cost reduction, we incorporated Sagemaker's new "Inference Components" capability to reduce the cost of hosting models before its general availability thanks to an early preview by AWS. This cost saving can be sometimes by as much as 50%, by re-using cloud resources across models.
A high-level representation of the AWS-side architecture for this part of the project is below:
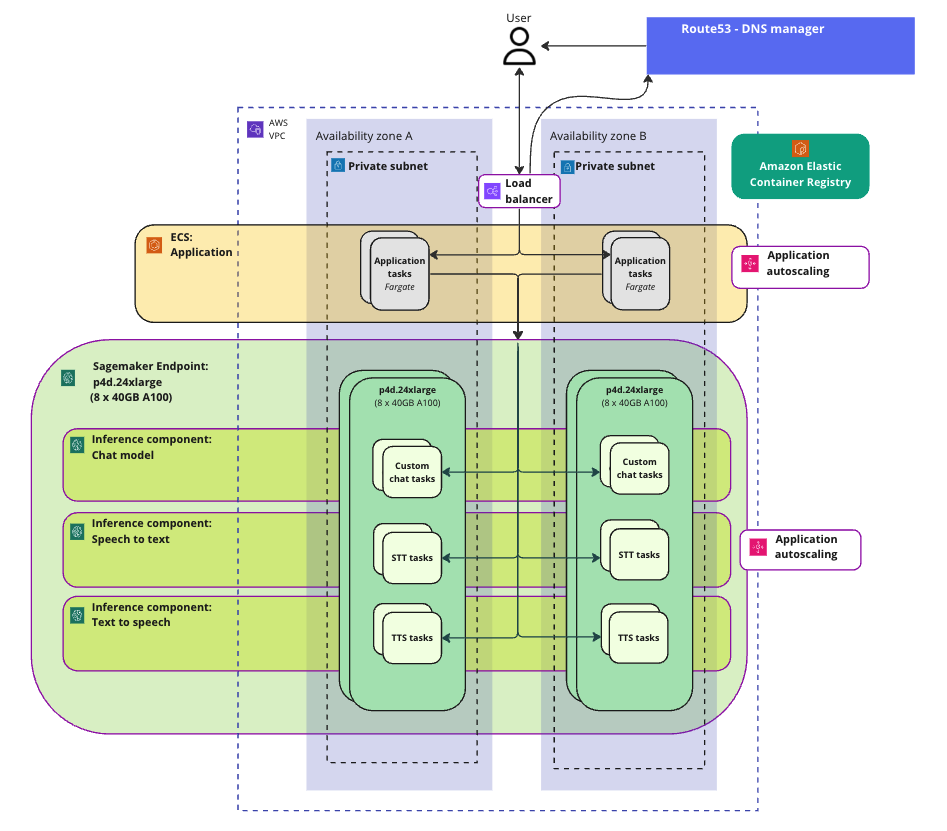
Responding quickly to Conjecture's evolving needs and opportunities, Daemon enabled 13 more large language models provided by Huggingface TGI ("text generation interface") on Sagemaker. It was possible to do this easily because of the integration layer we had provided and Sagemaker's out-of-the-box capabilities. We provided an online configuration capability where users could simply configure the details of the model they needed to deploy.
As Conjecture's needs evolved, and with a renewed emphasis on their core Cognitive Emulation offering, Conjecture saw the best way to get a cost-effective inference capability within their research function would be to host it on AWS, but it was also important to provide a smooth transition for Conjecture's researchers by providing a user experience as close as possible to services they were already using on their alternative cloud provider. Having worked to understand Conjecture's changing priorities, and responding to these evolving needs, Daemon applied its resources in this new direction. To provide a seamless transition, Conjecture and Daemon elected to develop further an EC2/ECS solution for hosting Conjecture's custom containers for research purposes. Below is a high-level representation of the AWS-cloud architecture for this project.

The Outcome
Daemon successfully deployed Conjecture's custom AI models on Amazon Sagemaker and offered additional features utilising the capabilities of Sagemaker and its Huggingface integrations. Conjecture now benefits from AWS's high-quality scalable infrastructure. As a result of Daemon's support of their pivot to the use of AWS for their research function, Conjecture obtained a seamless transition to the use of AWS containerised compute for inference.
Benefits
The benefits of utilising AWS for model inference hosting include:
- Reliable and efficient network and compute infrastructure. As a result of shifting the speech to text capabilities to AWS we were able to show 100-500ms improvements in end to end latency for the speech to text component in parts of the world due to AWS' extensive network.
- A huge partner and knowledge ecosystem.
- Quality of Service guarantees.
- A variety of abstractions and services for hosting.
The benefits of utilising Sagemaker for inference include:
- Managed scalable service and accessible interfaces for quick production-ready development.
- Out of the box integration with the complete Sagemaker family of products from training to explainability, as well as external services like Huggingface.
The benefits of utilising Sagemaker Inference Components for inference include:
- Up to 50% cheaper deployments because of re-use of cloud resources.
The benefits of using Daemon as an integration partner included:
- AWS and deep AI/ML expertise all in one place.
- Experienced and knowledgeable engineers and experts across the spectrum of delivery capabilities to support in-house capabilities.
- Fast augmentation in capacity to match the ambition.
Testimonials
"Partnering with Daemon was a great strategic move for our business as this key relationship helped migrate our models and systems into AWS seamlessly. Daemon unlocked and enabled our existing custom research workflows while collaborating with us to find and enhance our performance and scalability within AWS. We needed a mix of advanced AI/ML and cloud experience for this project, of which Daemon brought in abundance. Daemon's understanding of the latest technologies, ideation approach, and knowledge of our business provided substantial tangible benefits to the project as our needs evolved."
- Mason Edwards, VP Product & Commercial, Conjecture
Related Resources

Machine Learning & AI / Case Study
Investment to Impact: Transforming "Enthusiastic Frustration into strategic momentum for Specsavers' AI-Enabled SDLC

Cloud / Case Study
Smart Cloud migration you can trust
